Bài viết trước tôi đã giới thiệu 18 concept trong thiết kế hệ thống mà các kỹ sư và các ứng viên cần phải nắm vững. Bài viết này trình bày 7 phương pháp thiết kế để giúp bạn hiểu các khái niệm chính về thiết kế hệ thống. Cho dù bạn là người mới làm quen với thiết kế hệ thống hay là một chuyên gia, bài viết này sẽ cung cấp cho bạn kiến thức và kỹ năng cần thiết để vượt trội trong cuộc phỏng vấn và sự nghiệp của mình.
1. The Google File System (GFS)
Google File System (GFS) là một hệ thống tệp phân tán do Google phát triển để lưu trữ và quản lý lượng lớn dữ liệu trên một cụm máy chủ. Bài viết này mô tả việc thiết kế và triển khai GFS. GFS được thiết kế để có tính sẵn sàng cao, khả năng mở rộng và khả năng chịu lỗi cao. Nó giải quyết những thách thức trong việc lưu trữ và xử lý lượng lớn dữ liệu với số lượng máy chủ tương đối nhỏ.
GFS dựa trên kiến trúc master-slave trong đó một chủ duy nhất điều phối tất cả quyền truy cập vào hệ thống tệp và nhiều ChunkServer lưu trữ dữ liệu. Hệ thống được tối ưu hóa cho khối lượng công việc có thông lượng cao, độ trễ thấp, điển hình cho các ứng dụng của Google, chẳng hạn như Google Search và Google Maps.

2. Bigtable: Hệ thống lưu trữ phân tán cho dữ liệu có cấu trúc
Bài viết này mô tả việc thiết kế và triển khai Bigtable, một hệ thống lưu trữ phân tán được Google sử dụng để lưu trữ và quản lý lượng lớn dữ liệu có cấu trúc như trang web, hình ảnh và các loại dữ liệu khác. Bigtable được xây dựng để khắc phục những hạn chế của cơ sở dữ liệu quan hệ truyền thống và cách nó được tối ưu hóa để có thông lượng ghi cao, độ trễ thấp và khả năng mở rộng.
Bigtable sử dụng bản đồ được sắp xếp đa chiều có tính phân vùng cao, phân tán và liên tục. Dữ liệu được phân vùng thành các bảng và mỗi bảng được lưu trữ trên một máy chủ khác nhau, mô tả các lựa chọn thiết kế đã được thực hiện để đạt được hiệu suất cao, khả năng mở rộng và độ tin cậy, bao gồm phân vùng dữ liệu, sao chép và tối ưu hóa hiệu suất. Google sử dụng Bigtable để xây dựng các hệ thống khác như công cụ tìm kiếm của Google và Google Earth.

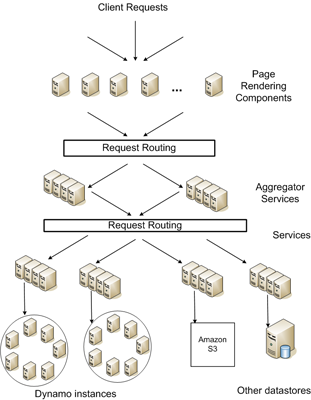
3. Dynamo: Amazon’s Highly Available Key-value Store
Mục này mô tả thiết kế và triển khai Dynamo, một hệ thống lưu trữ loại Key-value có tính sẵn sàng cao được Amazon sử dụng để cung cấp quyền truy cập dữ liệu có độ trễ thấp cho nền tảng thương mại điện tử của mình. Dynamo được xây dựng để khắc phục những hạn chế của các hệ thống tập trung truyền thống và cách nó được tối ưu hóa để có thông lượng ghi cao, độ trễ thấp và khả năng mở rộng.
Dynamo sử dụng bảng băm phân tán (distributed hash table) để phân vùng dữ liệu trên một tập hợp các node. Mỗi node chịu trách nhiệm cho một tập hợp con của dữ liệu và có thể xử lý các yêu cầu đọc và ghi đối với dữ liệu đó. Bài viết mô tả các lựa chọn thiết kế đã được thực hiện để đạt được hiệu suất cao, khả năng mở rộng và độ tin cậy, bao gồm phân vùng dữ liệu, sao chép và tối ưu hóa hiệu suất. Hệ thống cũng có cơ chế xử lý lỗi node, đảm bảo rằng dữ liệu vẫn khả dụng ngay cả trong trường hợp lỗi node.
4. Cassandra – A Decentralized Structured Storage System
Cassandra là một hệ thống lưu trữ có cấu trúc phi tập trung được sử dụng bởi các công ty như Facebook, Twitter và Netflix. Nó bao gồm các khái niệm chính như data partitioning, replication, and performance optimization.
5. The Chubby Lock Service for Loosely-Coupled Distributed Systems
Chubby là một dịch vụ khóa phân tán, có tính sẵn sàng cao được Google sử dụng để cung cấp sự phối hợp giữa các hệ thống phân tán.
Chubby cung cấp một cơ chế đơn giản, có tính sẵn sàng cao và độ trễ thấp cho các hệ thống phân tán để điều phối quyền truy cập vào các tài nguyên được chia sẻ, chẳng hạn như dữ liệu cấu hình và thỏa thuận cấp độ dịch vụ. Chubby sử dụng kiến trúc master-slave trong đó master điều phối tất cả quyền truy cập vào dịch vụ khóa và nhiều bản sao lưu trữ dữ liệu. Hệ thống được thiết kế để có khả năng chịu lỗi và cung cấp cơ chế xử lý các lỗi master và lỗi slave, đảm bảo rằng dịch vụ vẫn khả dụng ngay cả khi xảy ra lỗi.

6. HDFS: Hadoop Distributed File System
HDFS là một hệ thống tệp phân tán và được xây dựng để lưu trữ dữ liệu phi cấu trúc. Nó được thiết kế để lưu trữ các tệp lớn một cách đáng tin cậy và truyền các tệp đó ở băng thông cao tới các ứng dụng của người dùng.

7. Log: Các kỹ sư cần biết
Tầm quan trọng của cấu trúc dữ liệu log và vai trò của nó trong xử lý dữ liệu thời gian thực, thống nhất để xử lý dữ liệu có thể được sử dụng để xây dựng các hệ thống có khả năng mở rộng, chịu lỗi, đối với bất kỳ ai quan tâm đến các hệ thống phân tán và xử lý dữ liệu thời gian thực.
Kết luận
7 phương pháp này cung cấp sự hiểu biết toàn diện về các khái niệm và nguyên tắc chính của thiết kế hệ thống, cũng như các mẹo thiết thực để tiếp cận các vấn đề và cập nhật các xu hướng của ngành. Bài viết mang tính chất giới thiệu tổng quan cho những ai quan tâm để tìm hiểu sâu hơn để trang bị cho mình những kiến thức hữu ích để chuẩn bị tốt cho cuộc phỏng vấn thiết kế hệ thống của mình, đồng thời có kiến thức và kỹ năng cần thiết để trở nên xuất sắc trong sự nghiệp của mình.
Nguồn: Tham khảo Internet
Tham khảo thêm các bài viết:
- System design basics: forward proxy vs reverse proxy
- Difference between forward proxy and reverse proxy
- 18 concept trong thiết kế hệ thống mà các kỹ sư và các ứng viên cần phải nắm vững
CÔNG TY TNHH GIẢI PHÁP VNTT (VNTTS) – Chuyên cung cấp các sản phẩm, giải pháp, dịch vụ chuyển đổi số cho doanh nghiệp.
- Văn phòng TP.Hồ Chí Minh: Phòng 1908 & 1909, Tầng 19, Toà nhà Saigon Trade Center
- Văn phòng Bình Dương: Tầng trệt, Tòa nhà BBI, Đại học Quốc tế Miền Đông (EIU)
- Điện thoại: 0274.222.1012
- Email: chuyendoiso@vntts.vn
- https://vntts.vn



